什么是LLM
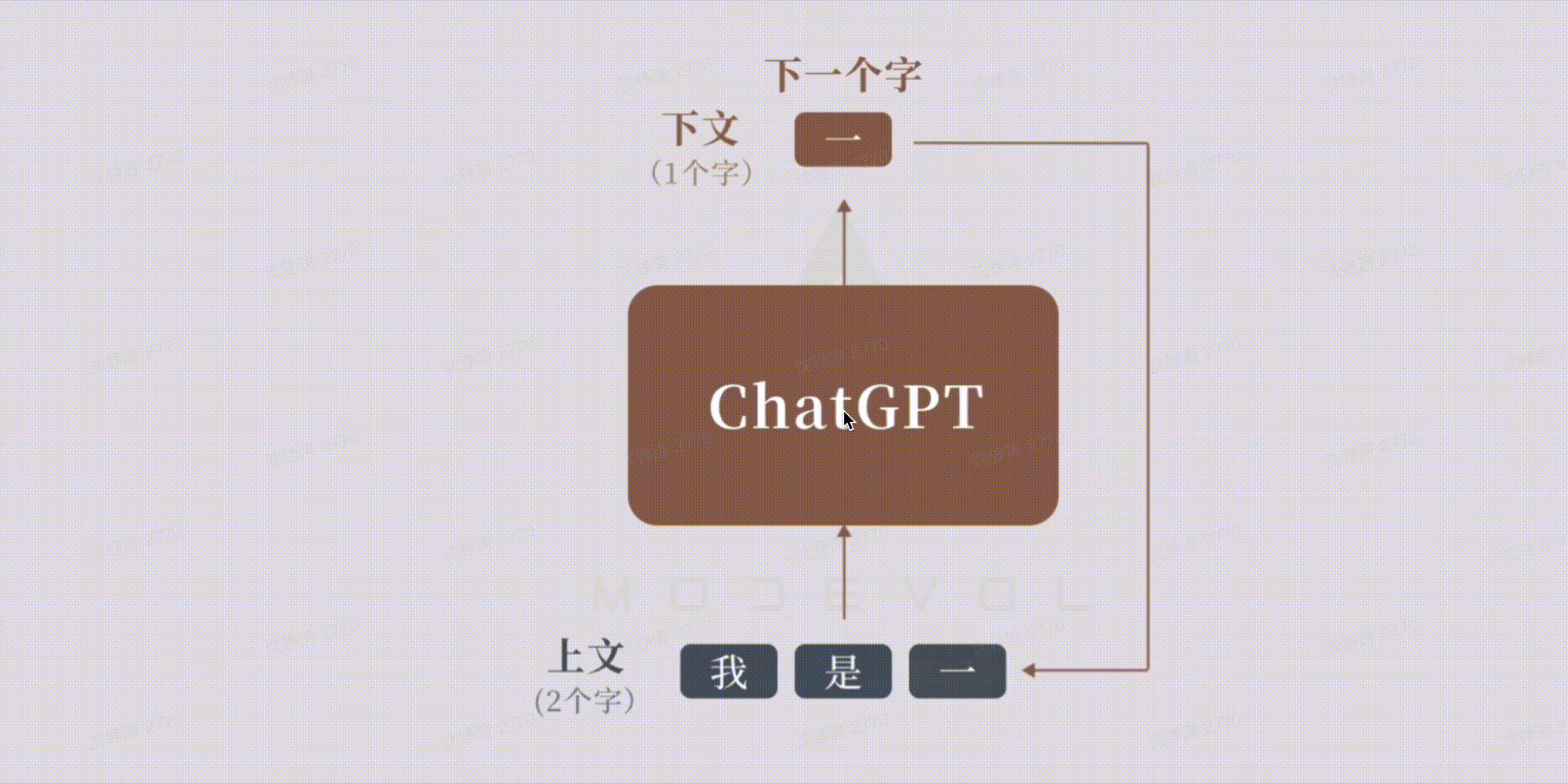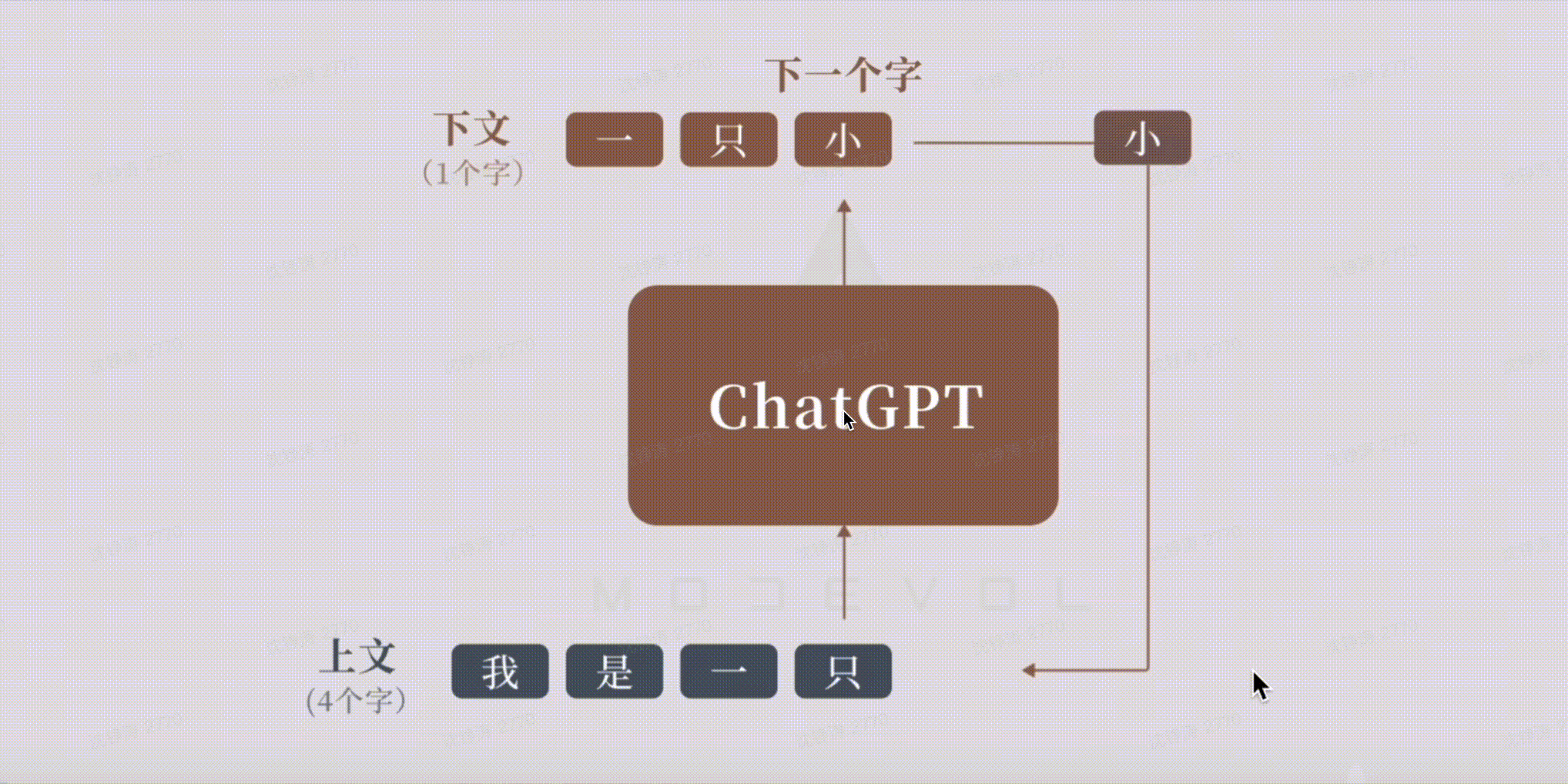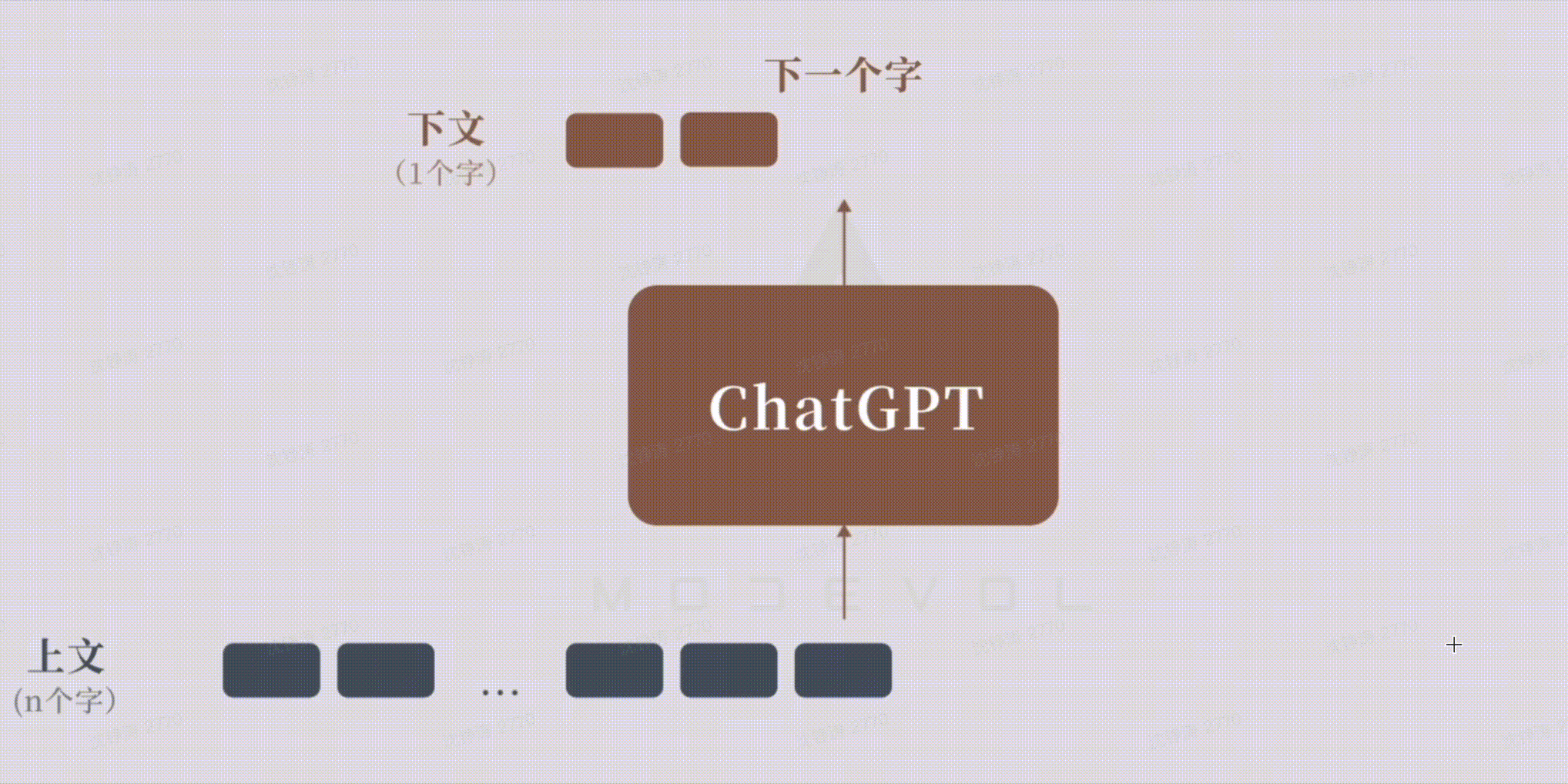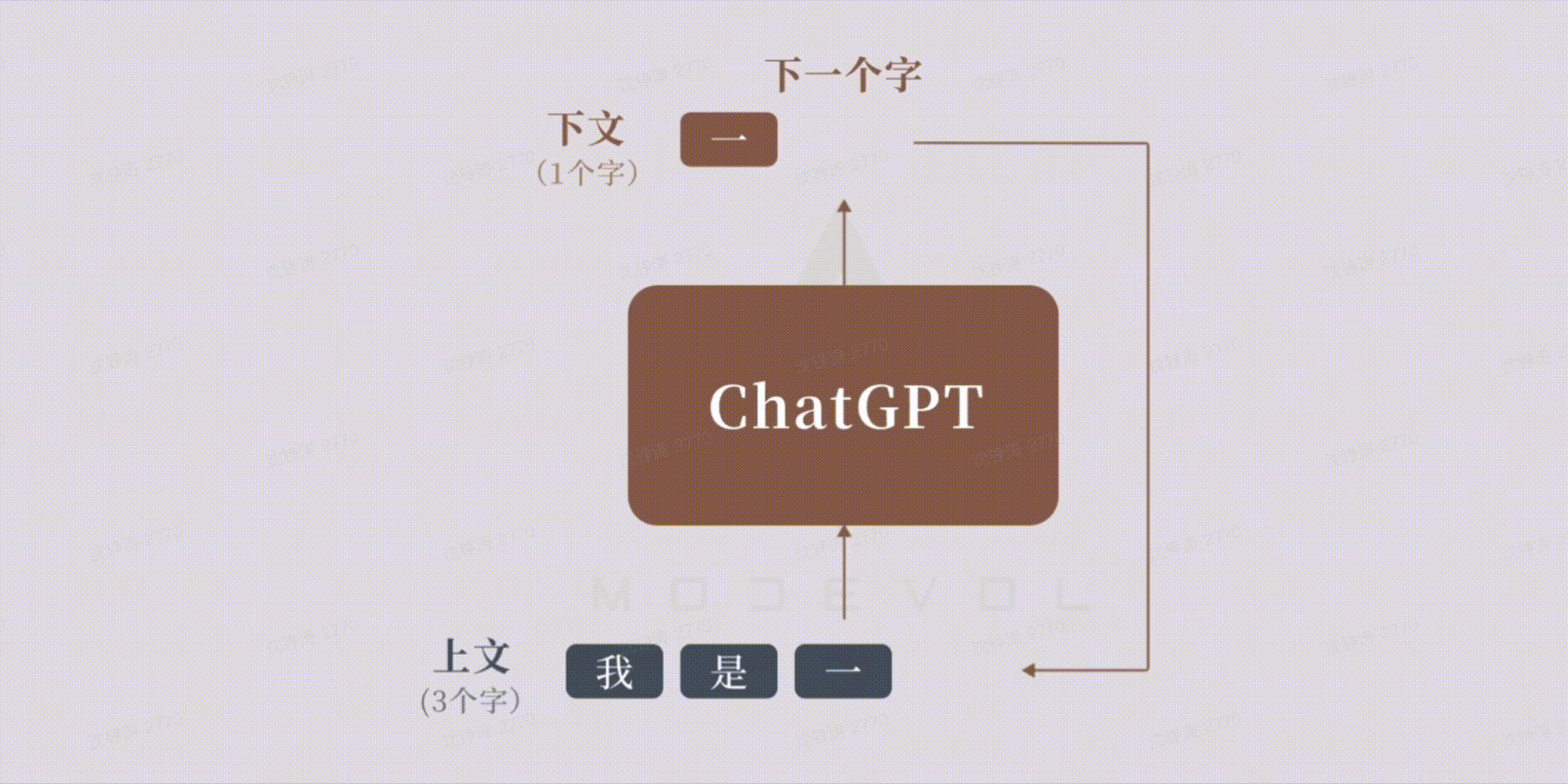
LLM:根据前文不断预测生成下一个词。Token作为达模型的内部语言,可以表达各种语言的元素,如词,标号等,按照特定的规则组合,就能表达出复杂的语义。
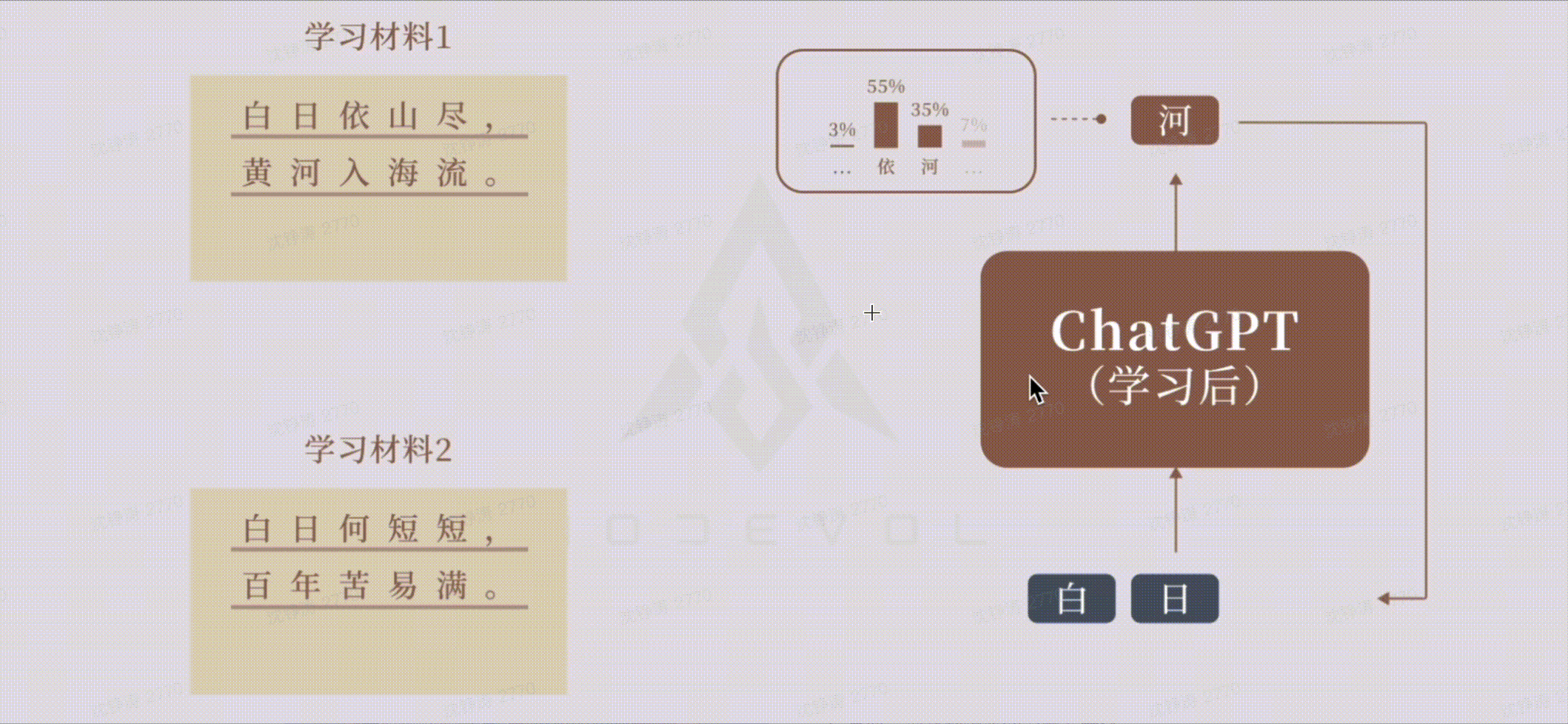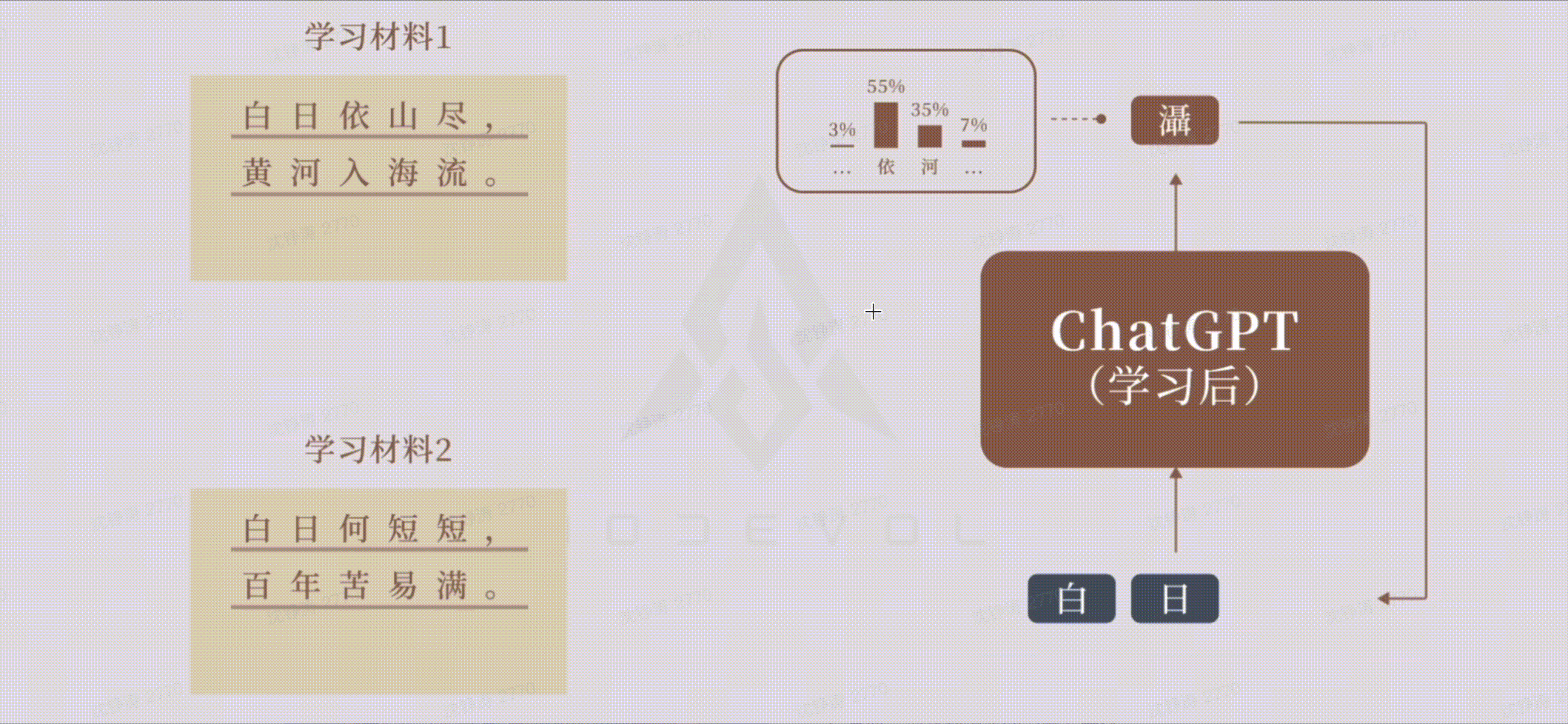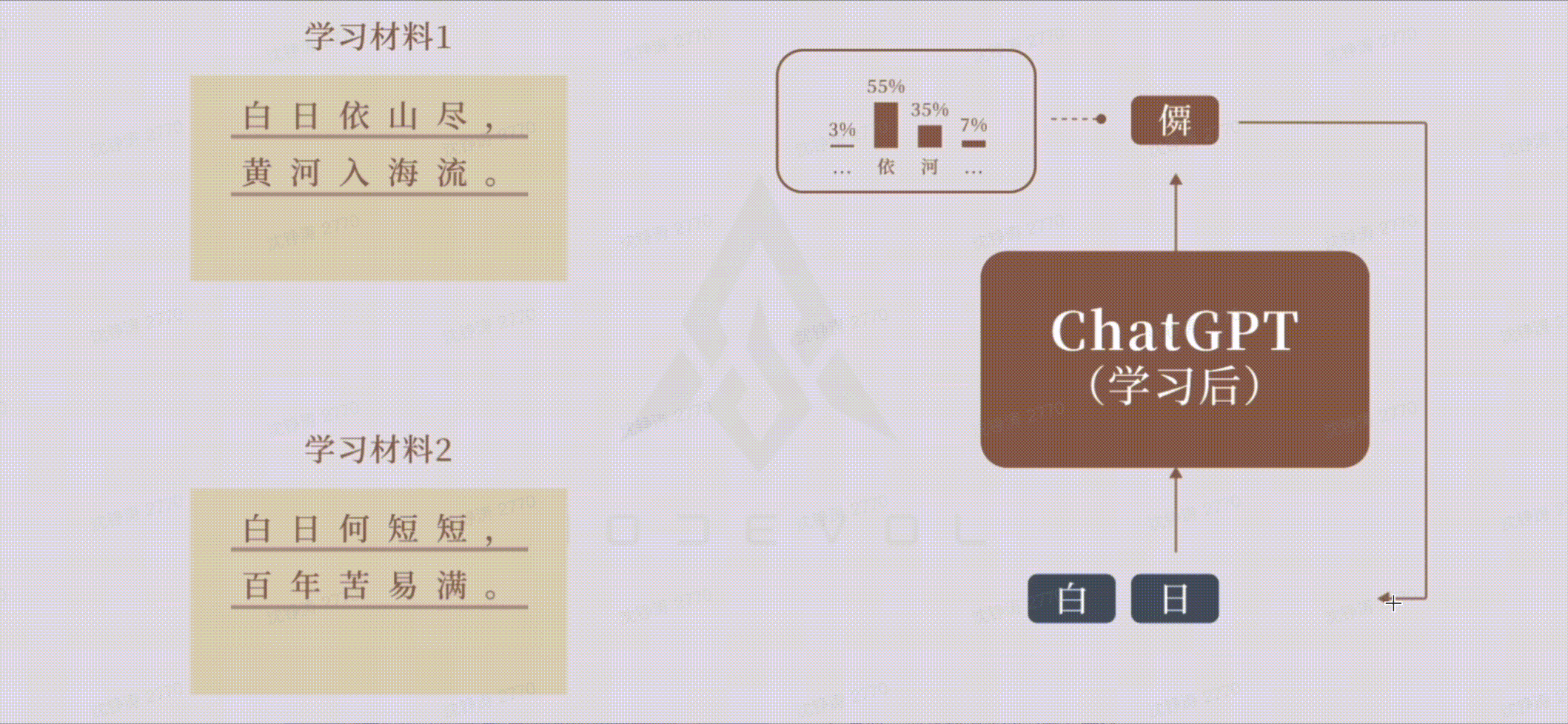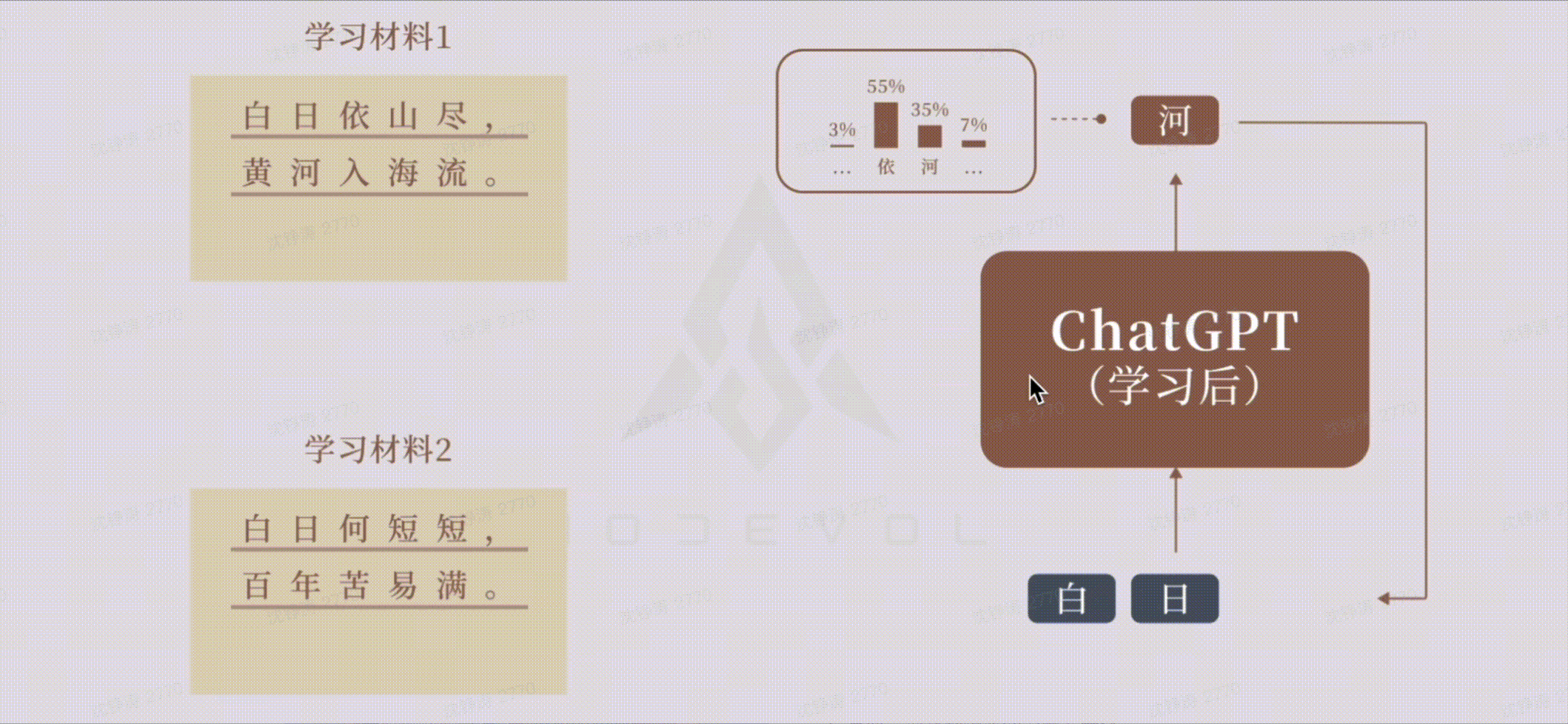
大模型学习&&生成过程:
大模型 VS 搜索引擎: 搜索引擎类似于图书馆的书架(检索工具),用户根据自己的需求在图书馆,按照区域/书架查找书籍。搜索引擎主要提供直接的信息,没有大模型的理解,推理和创造能力。 大模型类似于图书管理员,可以根据自己的经验,综合用户的需求,给出答案。大模型不仅提供信息,还能综合和创新使用这些信息,给出更加丰富和深入的回答。
基础原理
机器学习
机器学习主要分为两类:
- 回归:预测出一个值,给出一个具体的结果。
- 分类:给事物打上标签,作出分类选择。
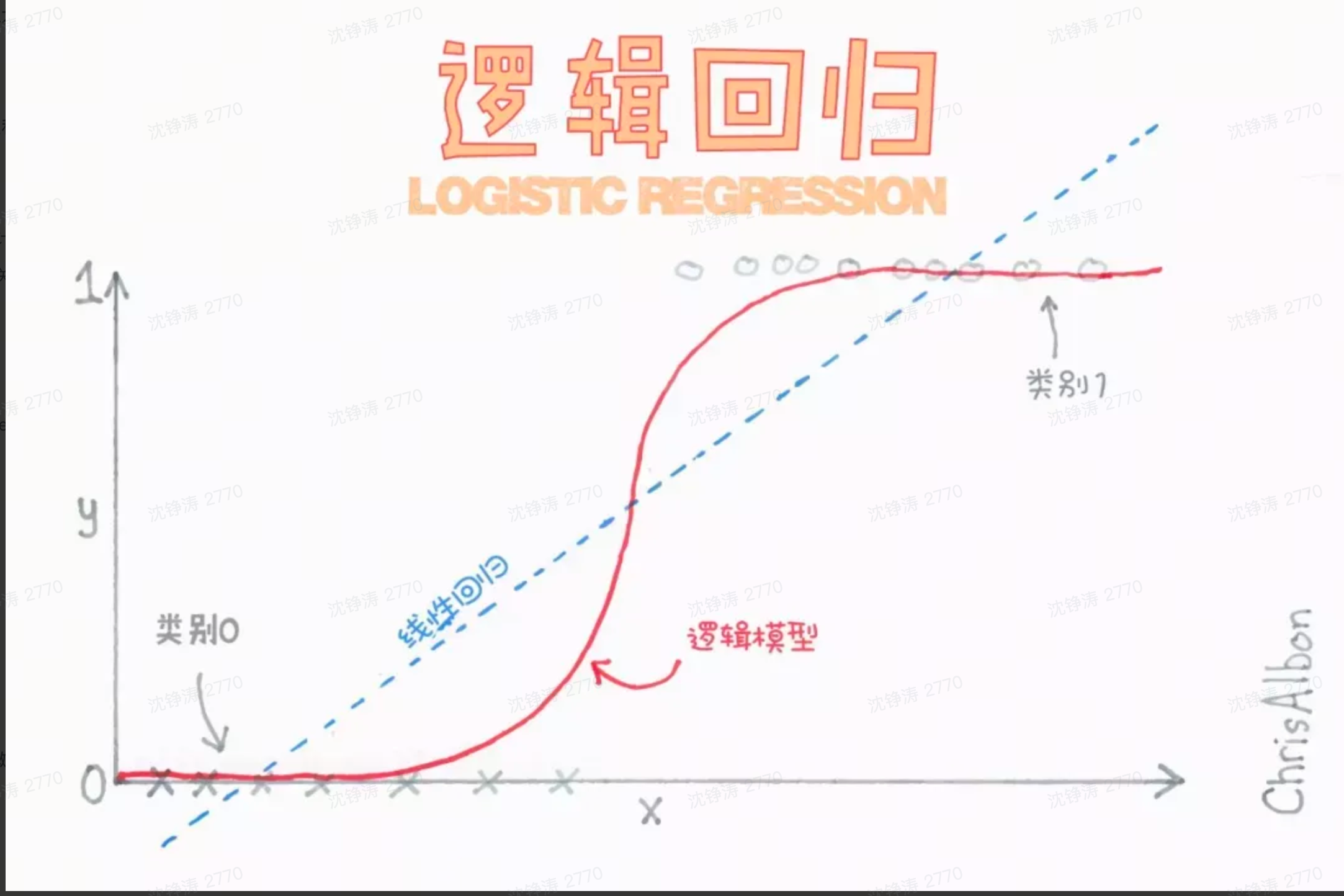

深度学习是机器学习的分支,是以人工神经网络为架构,对资料进行表征学习的算法。深度指的是在神经网络中使用的层数。
机器学习中有各式各样的算法模型,如KNN,SVM,CD4,决策树,贝叶斯等。本质上这些都是实现从一个样本到样本标记值的映射f(x) -> Y.
神经网络
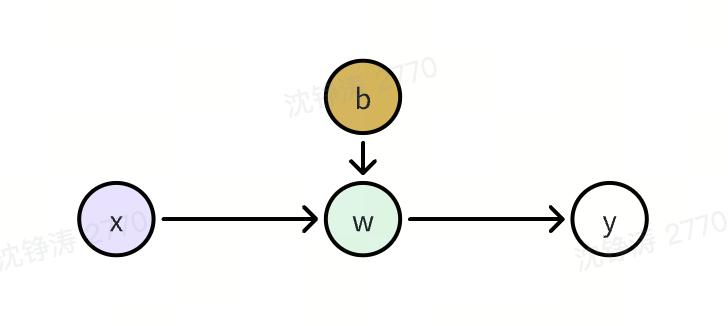
最简单的神经网络(只有一个神经元)就是一个线性模型:y = w * x + b. 神经元模型是个包含输入,输出和计算的模型。
实际应用中,基本使用的是多层神经网络。把需要的计算的层次称为计算层(“隐藏层”)。只有一层计算层的神经网络,就是一个单层神经网络。
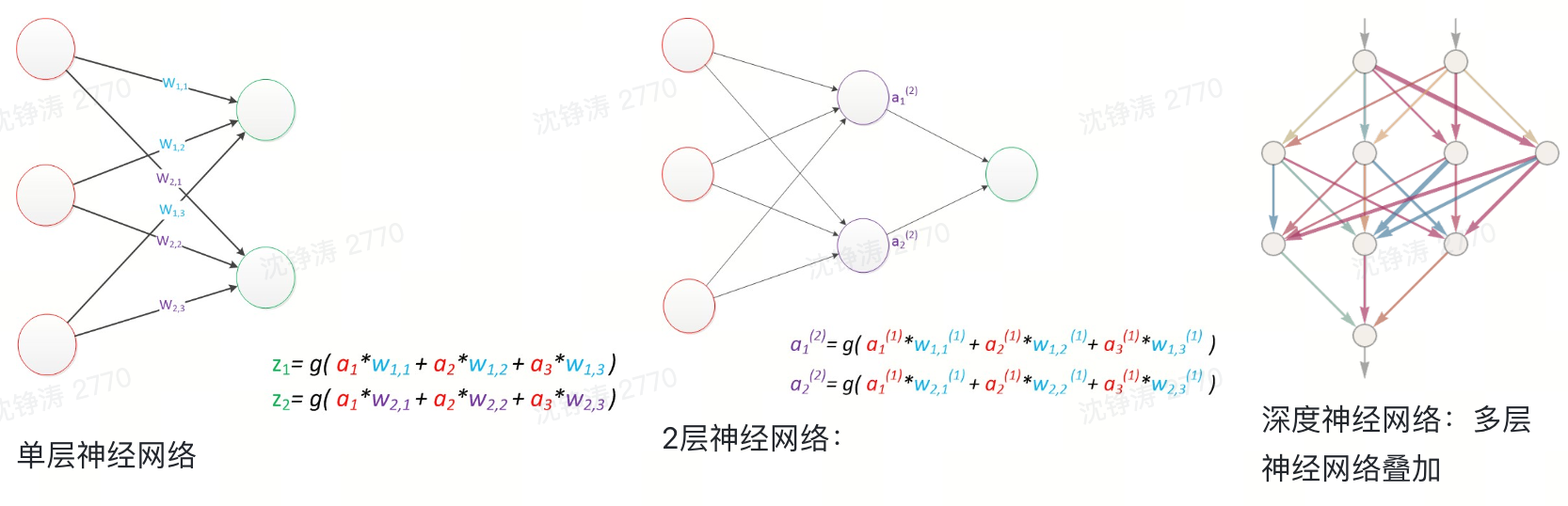
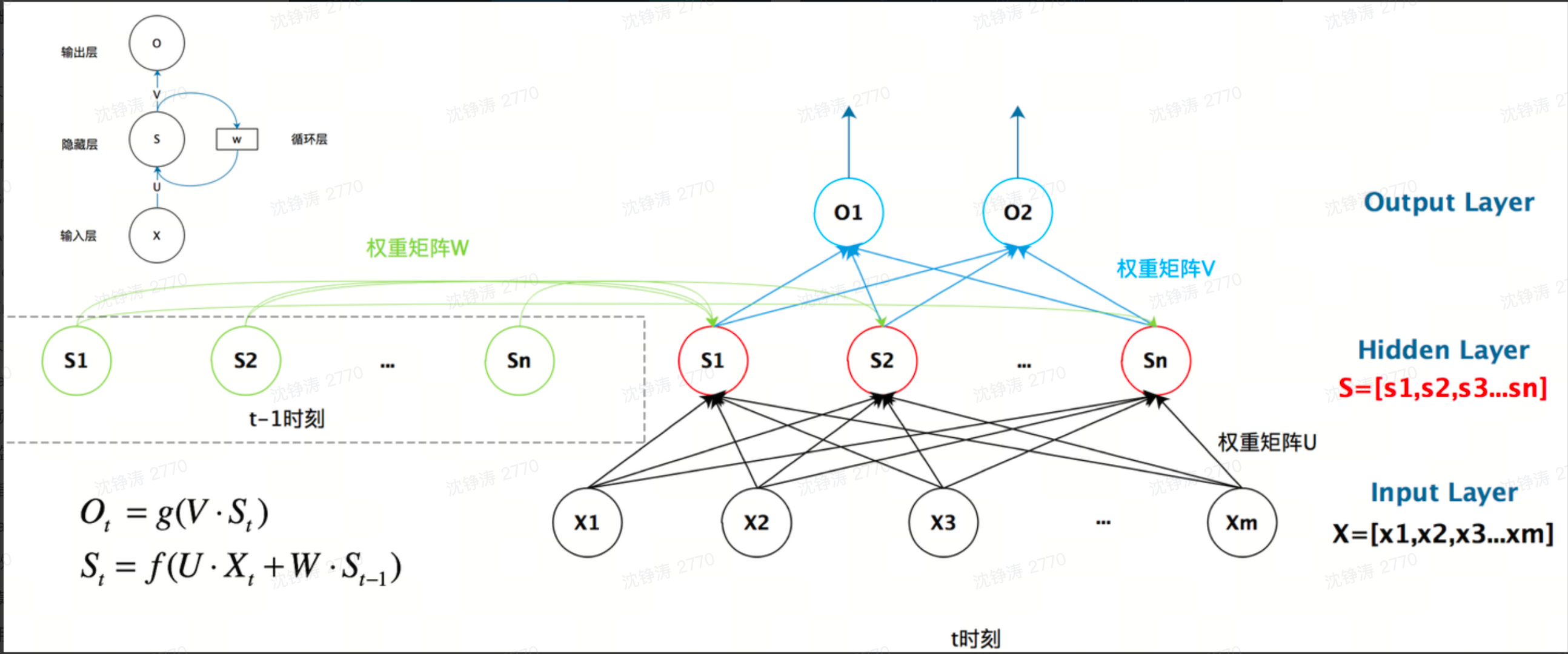
常见的神经网络是一个输入对应一个输出。不同的输入之间是没有关联的。但在某些现实场景下,不同的输入之间是有关联的(如根据选词填空时,每个词作为输入,词之间的顺序也是关键的)。
这里就需要RNN(循环神经网络),用以处理序列数据 —— 一串相互依赖的数据流。在计算层的神经元上做了进化,增加了一个S参数用于影响输出。S用来表示这次的输入X与上层的S。
LLM(大语言模型)
几乎所有的LLM模型都基于2017年Google提出的Transformer模型进行演变。(论文attention is all you need)
Transformer
本质是一个神经网络。从RNN变种而来,引入了“注意力”机制,使得模型能够更关注输入中的关键信息。被广泛应用于seq2se2上。相对于RNN模型,摒弃了RNN的顺序处理的方式。
大模型的大就在于参数的数量大。GPT的演变:

seq2seq:从一个序列映射到另一个序列。(机器翻译,从A语言的一句话转为B语言;Chat领域,将A问题转为B答案)。
为什么不使用RNN
- 难以并行:RNN的每一层都需要依赖上一层的输出,导致无法并行处理。
- 全局依赖:重要的信息可能在早期就进入模型,无法保留或影响保留较少,影响模型的表现。
- 内存开销:重要信息在传递过程中保留导致内存开销大。
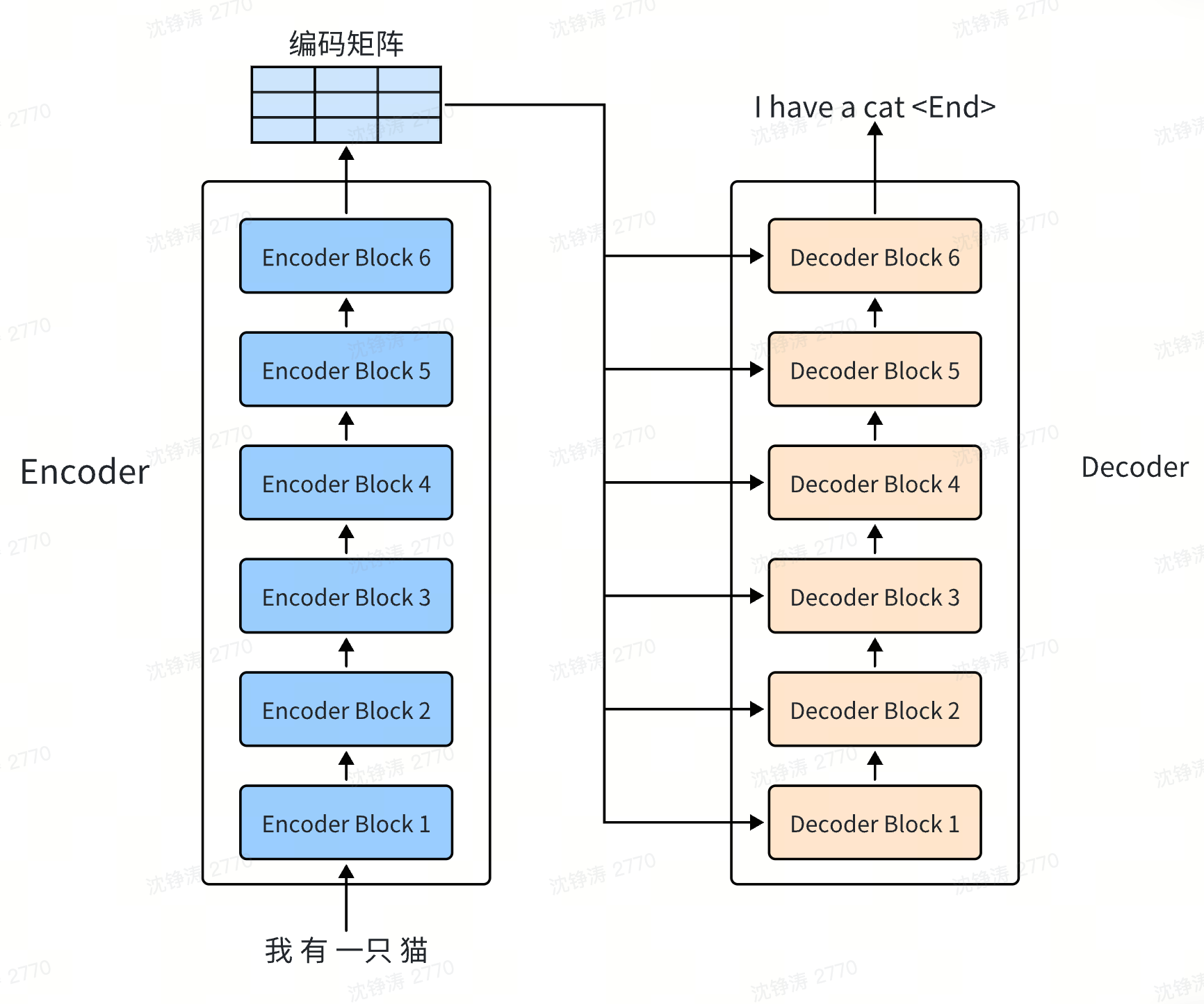
Encoder和Decoder分别是编码和解码,都为神经网络模块,分别做input的向量化处理和向量预测。是当前解决seq2seq的主流方案。
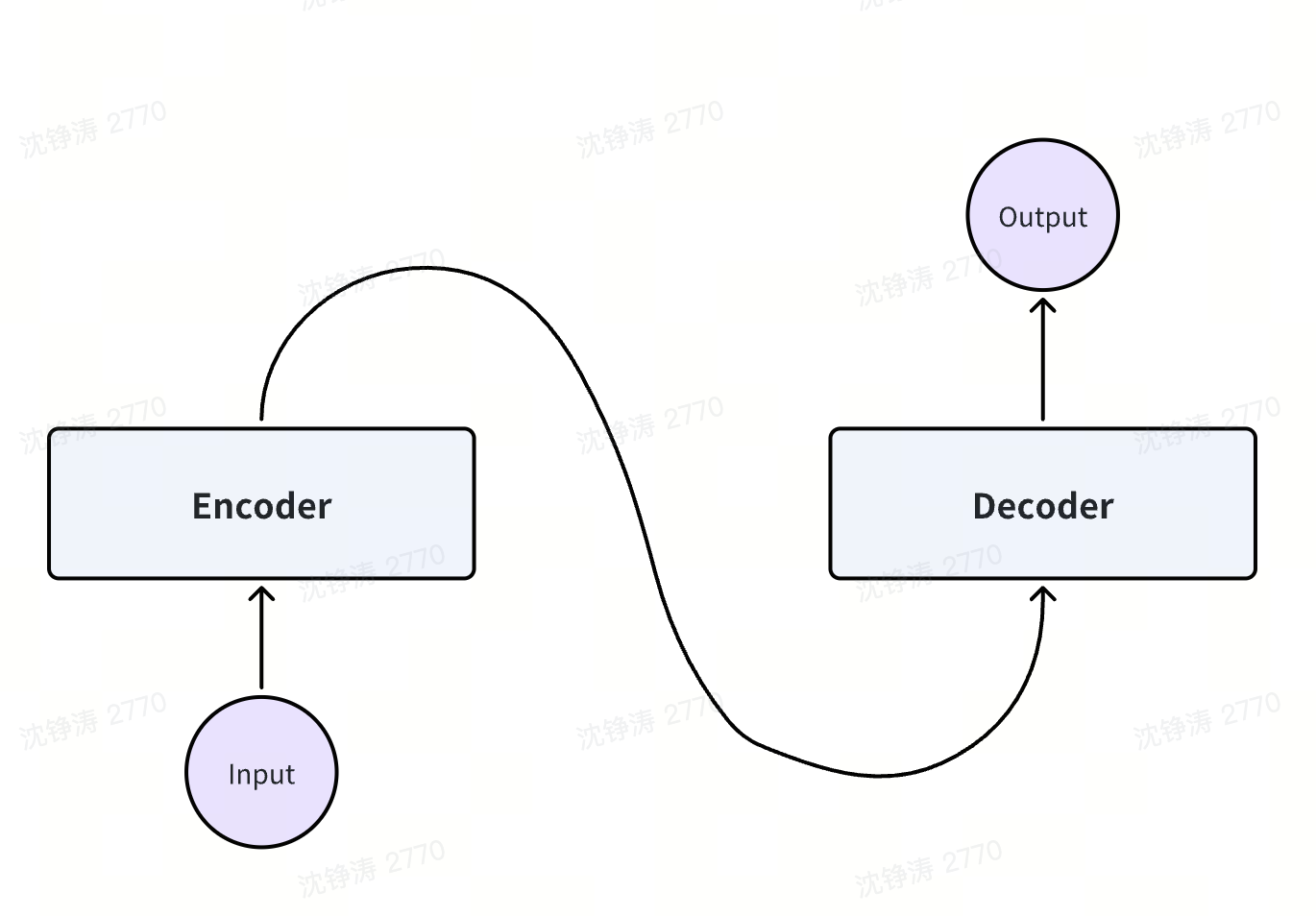
原理(原理细节后续再打开学习)
在训练阶段,把上下文输入做向量化压缩,交给神经网络,不断训练出各种参数的权重,得到一个大模型;在应用阶段,将上下文进行压缩,交给训练好的神经网络,得出一个概率分布最高的答案。
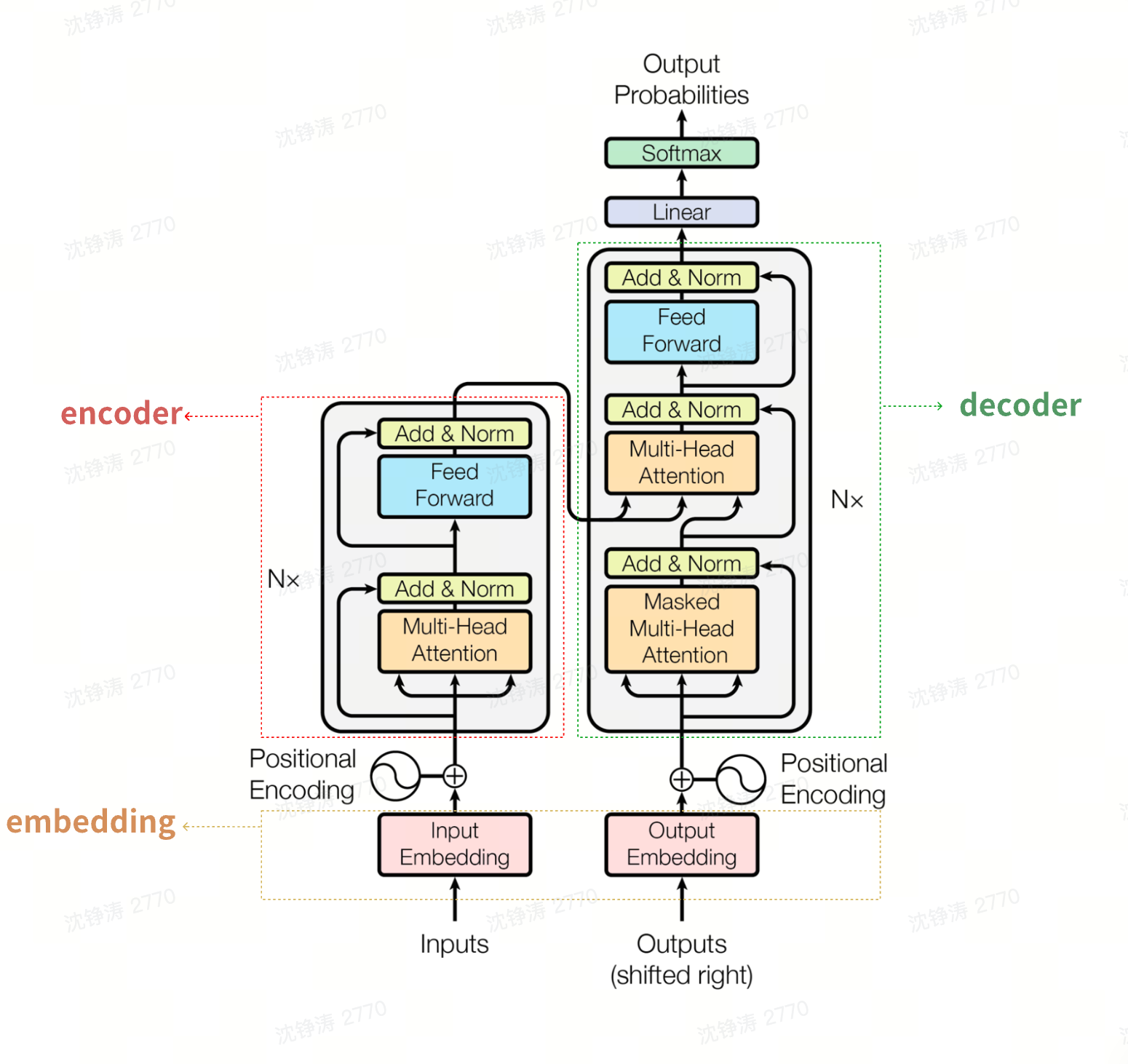
self-attention
本质上就是对已有信息进行向量化建模,利用Scaled Dot Product Attention(点放乘注意力),得出权重。

mult-head attention对于参数Q(query), K(key), V(value)是自学习的。
ADD & Norm
本质上在解决L+1层模型受L层变动时带来的分布影响,加快模型的收敛,提升训练速度。ADD为残差网络,Norm为归一化神经网络模型。
Feed Forward
对先前结果进行分类和回归(提炼总结),使结果更加精确。
Encoder & Decoder
是个模块,结构,思想,非实际的模型。
训练过程
训练方案
- 无监督预训练(%99的时间)
- 监督微调:收集少量高质量数据,进行预测
- 指令微调(RLHF):从人类反馈中进行中学习。包括奖励建模与强化学习
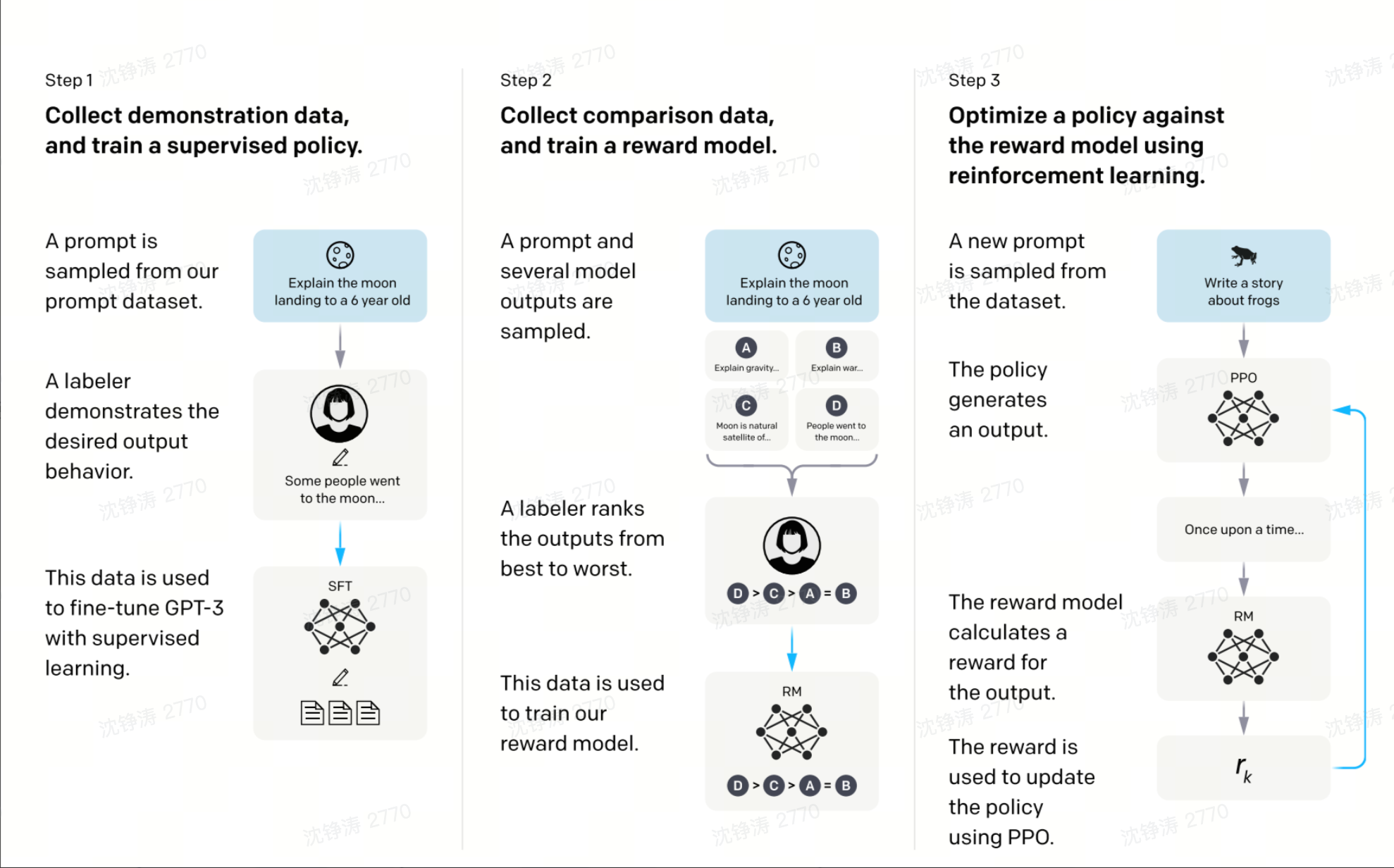
Chatgpt训练架构
分布式训练提升训练速度。分为数据并行与模型并行。
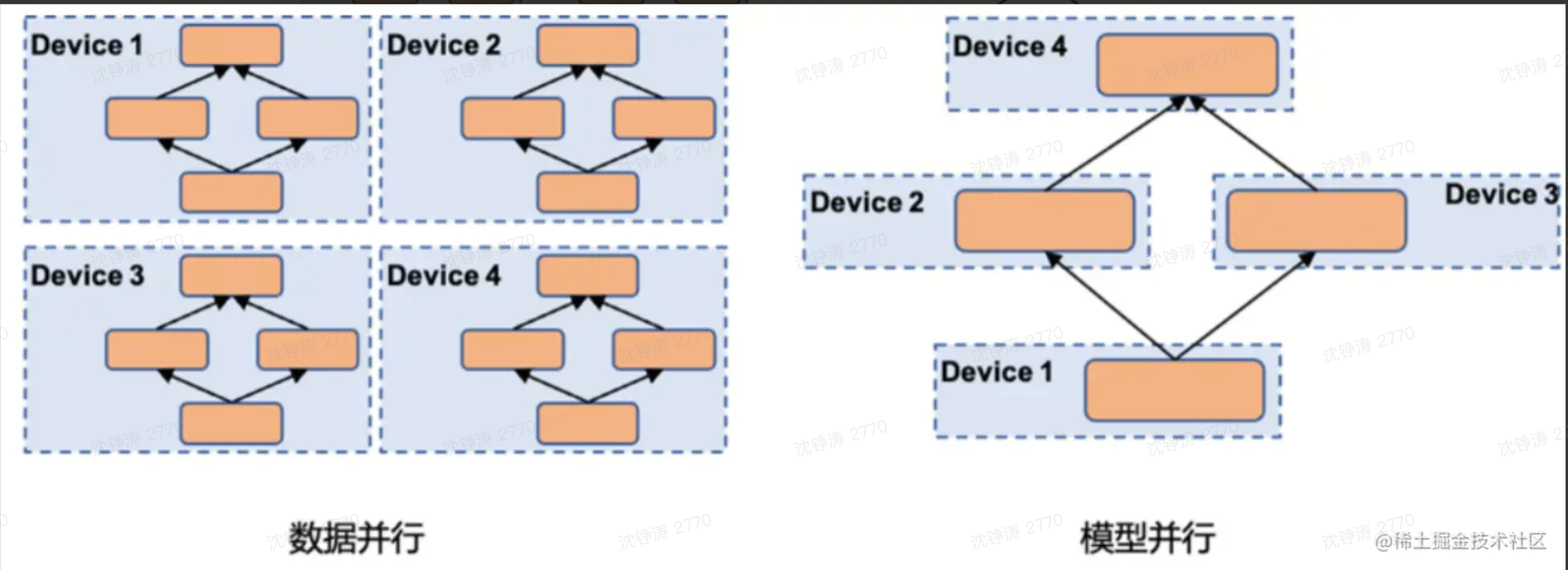
- 数据并行:模型分布在多个计算设备上(GPU or TPU)
- 模型并行:模型切割成几部分,分布在多个计算设备上
- 流水线并行:不同层划分到不同设备上,层间并行
- 张量并行:计算图中的层内参数划分到不同设备,层内并行
实际应用中的相关技术介绍
以chatgpt为例
Promt提示工程
上下文学习:使大模型在模型参数不进行更新时,仅通过在Promt上下文中包含特定问题相关的样例和信息,就可以使用LLM解决新问题。
Fine-Tunning微调
在一个预先训练好的模型上针对特定任务进行参数调整,微调方法有Adapter Tuning,LoRA,Prefix-Tuning等。
Fine-Tuning属于上述的监督微调。利用大模型内在低秩序特性,增加旁路矩阵模型全参数微调。LoRA将现在的通用大模型进行参数微调变成各个不同领域的专业模型。
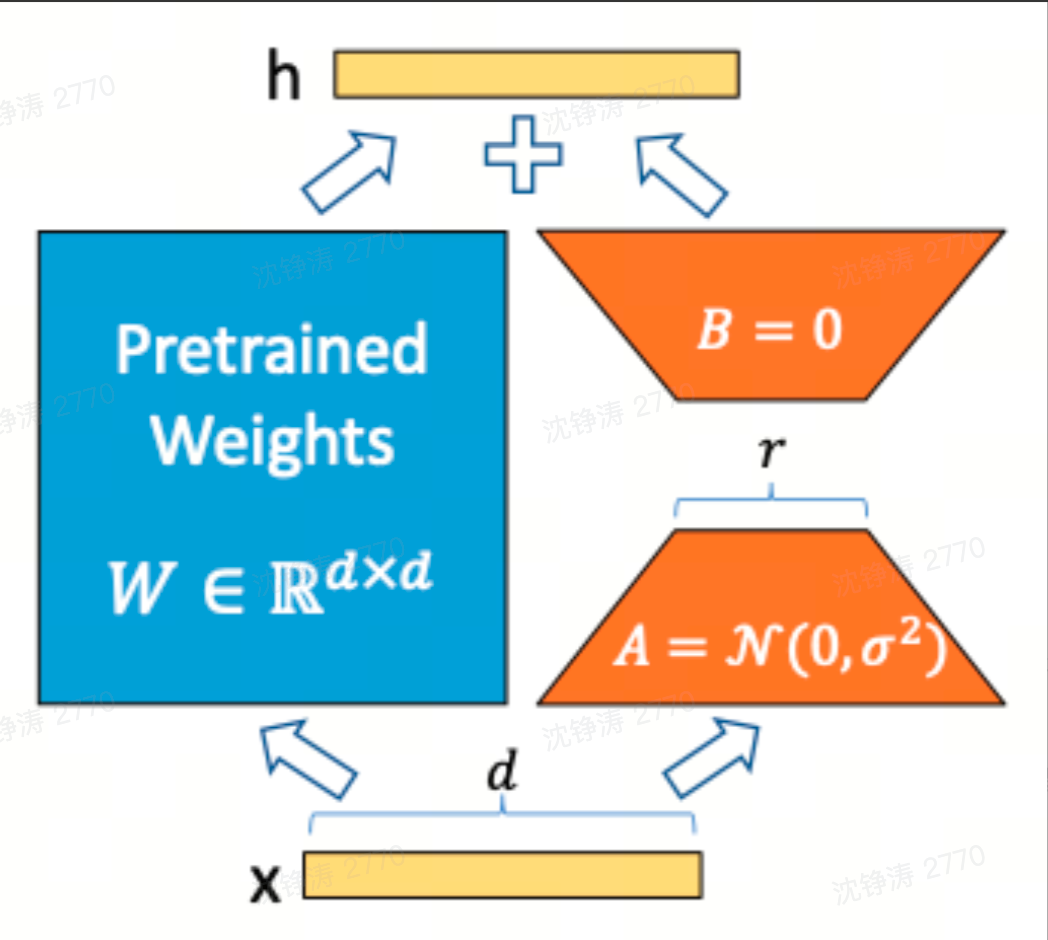
Embedding 工程
通过提前将数据进行“向量化”,将输入转为连续且稠密的高维向量,再喂给大模型。如让gpt去读一个1w字的pdf,此时就要借助embedding的技术。embedding本质上是RAT(检索增强技术),是gpt的外挂。
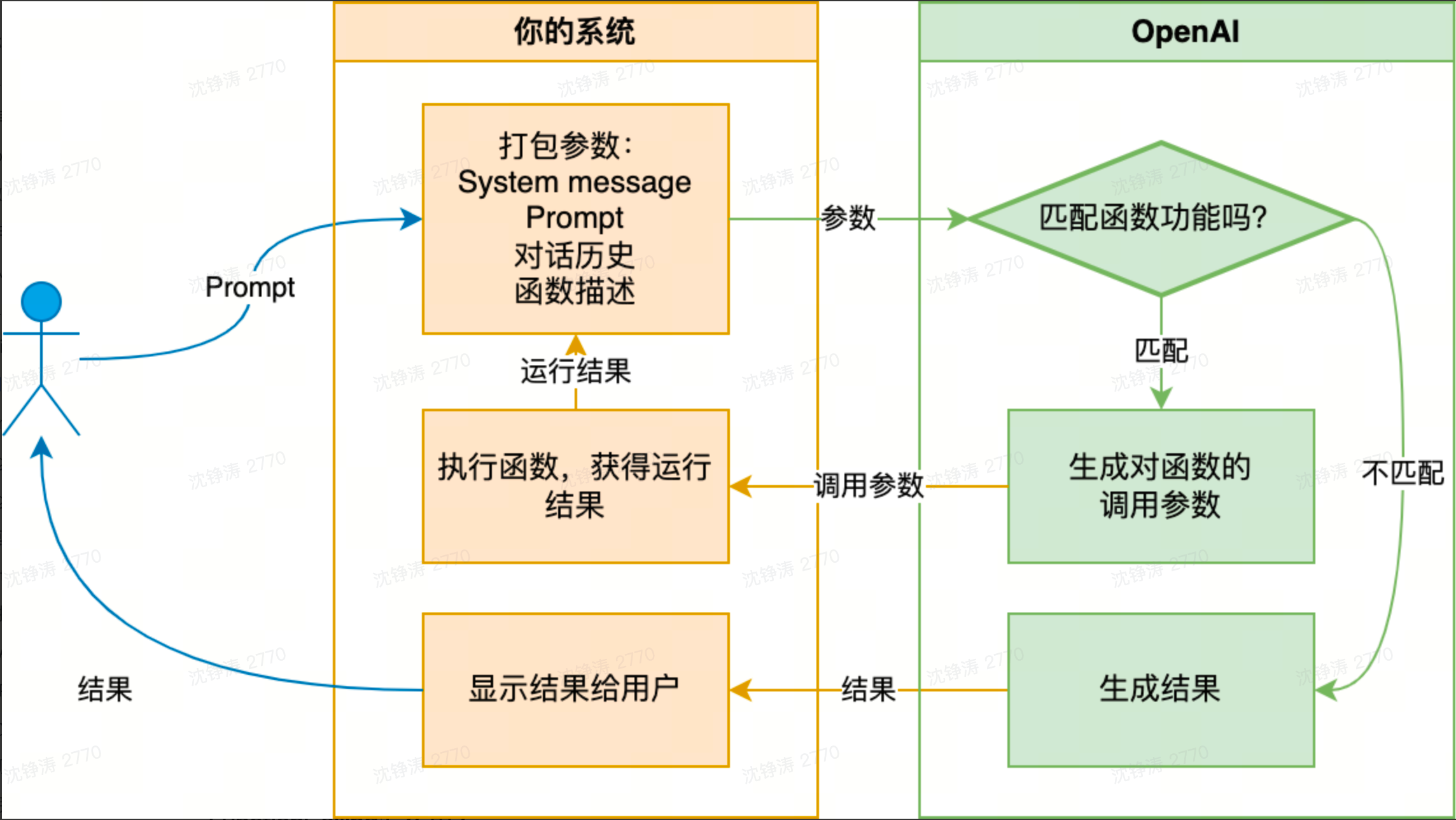
FunctionCalling
连接大模型业务系统的脚手架。